NLTK pos_tag(): Get the Part-of-Speech of Words in Sentence – NLTK Tutorial

In order to get the part-of-speech of a word in a sentence, we can use ntlk pos_tag() function. In this tutorial, we will introduce you how to use it.
![]()
NLTK is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) with python.
In this page, we write some tutorials and examples on how to use nltk libraries to process natural language processing (NLP) by following our steps.
In order to get the part-of-speech of a word in a sentence, we can use ntlk pos_tag() function. In this tutorial, we will introduce you how to use it.

When we are processing text, we often need to split text content to sentences, then split sentence to words. In this tutorial, we will tell you how to do using python nltk.
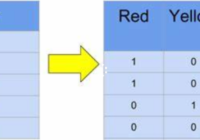
Encoding word n-grams to one-hot encoding is simple, however, it usually need large memory space. In this tutorial, we will introduce a new way to encode n-grams to one-hot encoding, it can create a one-hot matrix dynamically and need a little of memory space.
One-hot encoding is common used in deep learning, n-grams model should be encoded to vector to train. In this tutorial, we will introduce how to encode n-grams to one-hot encoding.
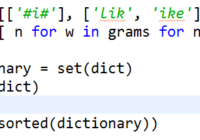
Flatten a python list is very useful to remove duplicated elements in python, which is can help us to build a word dictionary in nlp. In this tutorial, we will introduce you on how to flatten a multi-demensional python list.
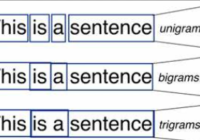
N-grams model is often used in nlp field, in this tutorial, we will introduce how to create word and sentence n-grams with python. You can use our tutorial example code to start to your nlp research.

The basic of word lemmatization in nltk is not perfect, in this tutorial, we will use word part-of-speech to improve its functionality. You can learn and do by following our tutorial.

In nltk, if you want to improve the efficiency of application, word parts-of-speech is a very useful way. In this tutorial, we will introduce how to tag and extract the parts-of-speech of words in a sentence.

NLTK contains many kinds of parts-of-speech, what are the meaning of them? In this tutorial, we will give you a full list about nltk part-of-speech and their examples.
Word lemmatization can help us to improve the similarity of sentences. In this tutorial, we will introduce on how to implement word lemmatization with nltk. You can learn how to do by following our tutorial.