Python 3 urllib is a package that helps us to open urls. It contains four parts:
- urllib.request for opening and reading URLs
- urllib.error containing the exceptions raised by urllib.request
- urllib.parse for parsing URLs
- urllib.robotparser for parsing robots.txt files
urllib.request and urllib.parse are most used in python applications, In this tutorial, we will introduce how to crawl web page using python 3 urllib.
Preliminaries
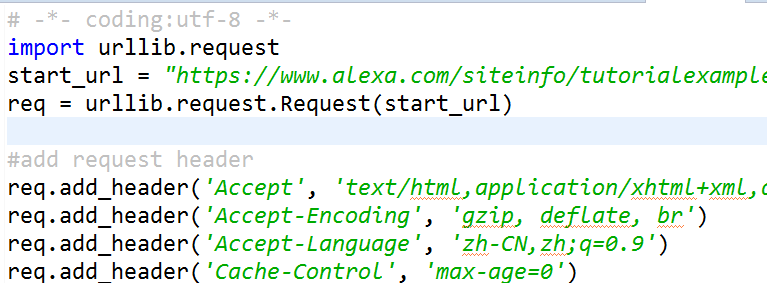
# -*- coding:utf-8 -*- import urllib.request
Set start url you want to crawl
start_url = "https://www.alexa.com/siteinfo/tutorialexample.com"
Build a http request object
We use http request object to connect web server and craw web page.
req = urllib.request.Request(start_url)
Add http request header for your request object
An Easy Guide to Get HTTP Request Header List for Beginners – Python Web Crawler Tutorial
#add request header
req.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8')
req.add_header('Accept-Encoding', 'gzip, deflate, br')
req.add_header('Accept-Language', 'zh-CN,zh;q=0.9')
req.add_header('Cache-Control', 'max-age=0')
req.add_header('Referer', 'https://www.google.com/')
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36')
Crawl web page and get http response object
response = urllib.request.urlopen(req)
If you want to know what variables and functions in response object. you can read this tutorial.
A Simple Way to Find Python Object Variables and Functions – Python Tutorial
Check response code and get web page content
response_code = response.status
if response_code == 200:
content = response.read().decode("utf8")
print(content)
Then a basic web page crawler is built.